




At Kubric, we have developed a Smart Gallery which gives creators & designers a single place to organise, manage and access their creatives. We constantly strive towards making our asset system feel as smooth and user friendly as the native file systems on Mac and PC. That’s why it was essential for us to develop a fast and seamless file upload solution. We have implemented several interesting techniques to achieve this goal. In this blog, I’ll be sharing what we have learned while exploring one such technique.
How does file upload work on Kubric?
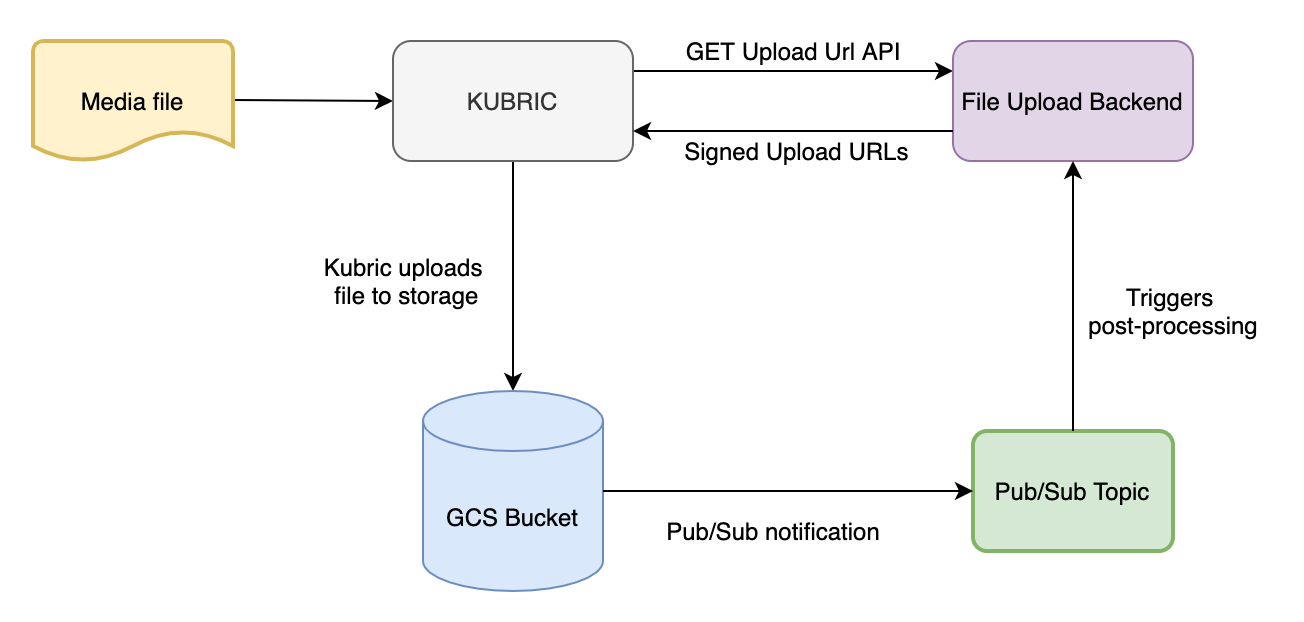
Our file upload solution has gone through several iterations of redesign with the objective of optimising for speed and to shave off every ms that we can. Before discussing the problem statement, let’s first get an understanding of how Kubric’s upload solution works.
After trying out a few different approaches we trimmed down our file upload pipeline to a two-step process:
- The client makes an API call (get_upload_url API) to fetch a signed upload URL, then it uploads the file object to a Google Cloud Storage bucket using that URL.
- As soon as the upload is finished, the system receives a pub/sub notification from cloud storage. We use this to trigger post-processing for the uploaded file object.
Room for improvement:
This simple upload process helped reduce our average file upload time but not by a significantly noticeable amount. We wanted to improve it further.
We noticed that the most time-consuming portion of this process is the part where a client uploads a file to the storage bucket. A straightforward idea to speed this up is to parallelise this step. So we put our thinking caps on and got to work!
Parellel Upload
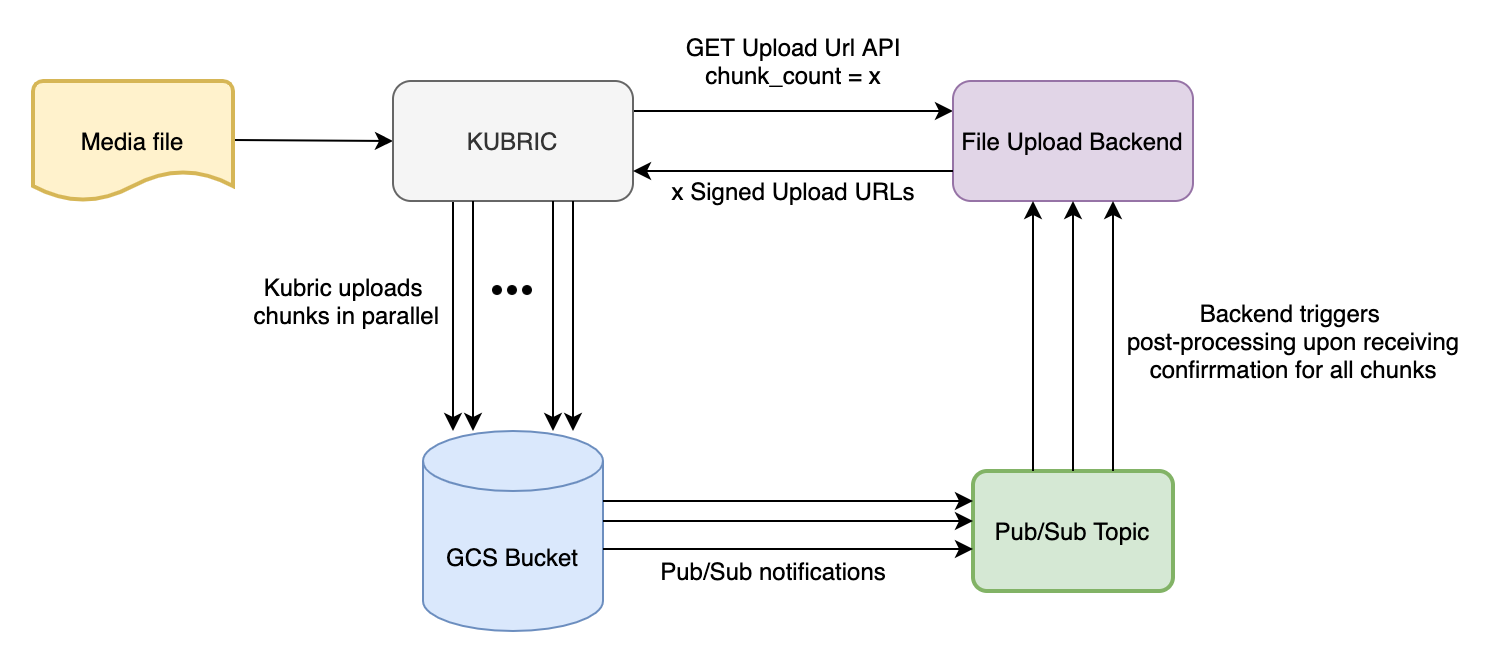
We found this great feature provided by GCP called Compose. It basically concatenates a list of uploaded blob objects into a single blob. In theory, this should allow you to break up a single file into multiple chunks which can then be uploaded parallelly resulting in significantly faster upload time(It turned out to be trickier than we thought, as is the case with everything. The devil lies in detail).
To test this hypothesis, we came up with the following upload pipeline:
- In our get upload url API, we ask for the number of chunks a client wants to divide up a file into.
- In the response object, we return a dictionary containing upload URLs corresponding to each chunk id.
- It’ll be the client’s responsibility to upload each chunk parallelly and to optimize this step for time.
- Once all the chunks get uploaded to the storage bucket, our asset system concatenates all chunk blobs into one single file blob using the GCP compose tool.
- After this, post-processing is triggered.
This process of chunking a file up, uploading in parallel and stitching them together at the end worked seamlessly.
Testing
First, we conducted some exploratory testing using a python script where all the chunks were uploaded parallelly on a separate thread. We noticed improvement in upload time for files larger than 20 Mb but not so much for smaller files.

But this was tested on a script. In order for us to be able to use this approach, we had to test parallel upload performance on Chromium-based browsers since Kubric lives on the web. Here, we got a mixed bag of results. This is because chrome manages multi-threading a bit more conservatively than our OS does. It does not allow a single page to use up more than 6 threads at a time plus using even that would throttle performance of the whole web page which is, obviously, unacceptable.
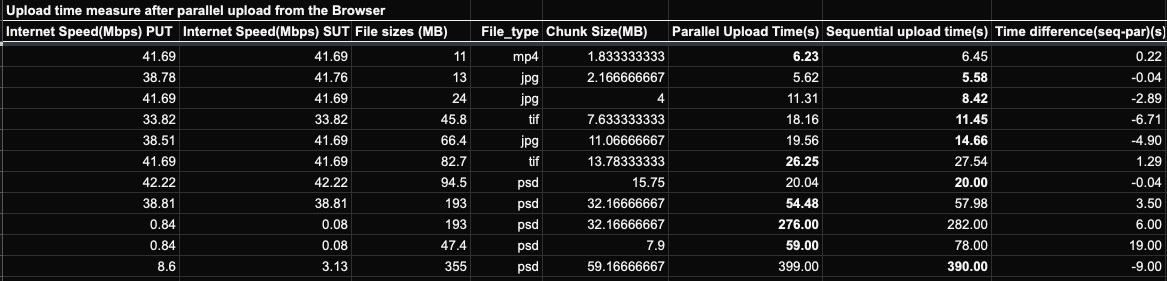
For this reason, on our UI, the chunk count had to be capped at 6. These constraints result in a limited room for optimization. We found that keeping the chunk count at 4 gave us the best results on average for file size ranging from 50Mb to 200Mb. The test results looked like this:
With low internet bandwidth:

With high internet bandwidth:
Observations

TLDR: As you might have already guessed, the results would depend on how efficiently a client can upload each chunk parallelly. If a client has the ability to fire up as many threads as they want, we observed that upload time can be reduced by upto 30%. We found out that they’d achieve better performance on average when the following criteria are met:

We are performing more experiments to arrive at a conclusion for files smaller than 20 Mb.
We observed the following behaviour after carrying out the above experiments a number of times:
- Without any multi-threading constraints, parallel upload can provide a substantial win over a sequential upload in terms of upload time. For this approach, we observed time reduction ranging from 20% to 30% depending on file size. It works best for large files(greater than 20Mb) and a chunk size of ~1Mb. For small files, the breakup/stitching overhead eats into time savings.
- On chromium browsers, with multi-threading constraints, we kept the chunk count at 4 and tested with different file sizes. Here, the results were kind of all over the place. We got one positive data point though, for file sized ranging from 50 to 100 Mb, we noticed significantly better results on average.
- Parallel upload times vary a lot depending on internet bandwidth. They are not inversely proportional to each other as one would expect them to be.
These observations look promising, but we think that we need to optimize the parameters further in order to achieve desired results in every scenario.
Conclusion
So, what did we learn from all this?
In conclusion, we have found that faster uploads can be achieved using the parallel upload technique we discussed above. But the performance benefit which we get from it depends strongly on the client’s ability to upload each chunk parallelly.
If we can utilize a full-fledged multi-threading approach, then the performance can be improved considerably. Otherwise, reduction in upload time is possible but it would need further optimization.
Next Steps
We’ll collect more file upload statistics at different internet bandwidth and try to arrive at an optimized config which will allow for a better experience for every user.




